728x90
반응형
📌 정렬 알고리즘 종류
| 정렬 알고리즘 | 정의 |
| 버블 (bubble) | 데이터의 인접 요소끼리 비교하고, swap 연산을 수행하며 정렬하는 방식 |
| 선택 (selection) | 대상에서 가장 크거나 작은 데이터를 찾아가 선택을 반복하면서 정렬하는 방식 |
| 삽입 (insertion) | 대상을 선택해 정렬된 영역에서 선택 데이터의 적절한 위치를 찾아 삽입하면서 정렬하는 방식 |
| 퀵 (quick) | pivot 값을 선정해 해당 값을 기준으로 정렬하는 방식 |
| 병합 (merge) | 이미 정렬된 부분 집합들을 효율적으로 병합해 전체를 정렬하는 방식 |
| 기수 (radix) | 데이터의 자릿수를 바탕으로 비교해 데이터를 정렬하는 방식 |
📌 퀵 정렬이란?
- pivot 값을 선정해 해당 값을 기준으로 정렬하는 방식
- 시간 복잡도 : O(nlogn) → 기준값 선정에 따라 큰 영향을 미침
📌 퀵 정렬 과정
- 데이터를 분할하는 pivot을 설정(아래 그림의 경우 가장 오른쪽 끝을 pivot으로 설정)
- pivot을 기준으로 다음 a~e 과정을 거쳐 데이터를 2개의 집합으로 분리
- start가 가리키는 데이터가 pivot이 가리키는 데이터보다 작으면 start을 오른쪽으로 1칸 이동
- end가 가리키는 데이터가 pivot이 가리키는 데이터보다 크면 end를 왼쪽으로 1칸 이동
- start가 가리키는 데이터가 pivot이 가리키는 데이터보다 크고, end가 가리키는 데이터가 pivot이 가리키는 데이터보다 작으면 start, end가 가리키는 데이터를 swap하고 start는 오른쪽, end는 왼쪽으로 1칸씩 이동
- start와 end가 만날 때까지 2-1~2-3 을 반족
- start와 end가 만나면 만난 지점에서 가리키는 데이터와 pivot이 가리키는 데이터를 비교하여 pivot이 가리키는 데이터가 크면 만난 지점의 오른쪽에, 작으면 만난 지점의 왼쪽에 pivot이 가리키는 데이터를 삽입
- 분리 집합에서 각각 다시 pivot을 선정
- 분리 집합이 1개 이하가 될 때까지 과정 1~3 반복 💡 코딩테스트에서 종종 나오는 유형이므로 재귀함수의 형태로 직접 구현해볼 것을 추천!
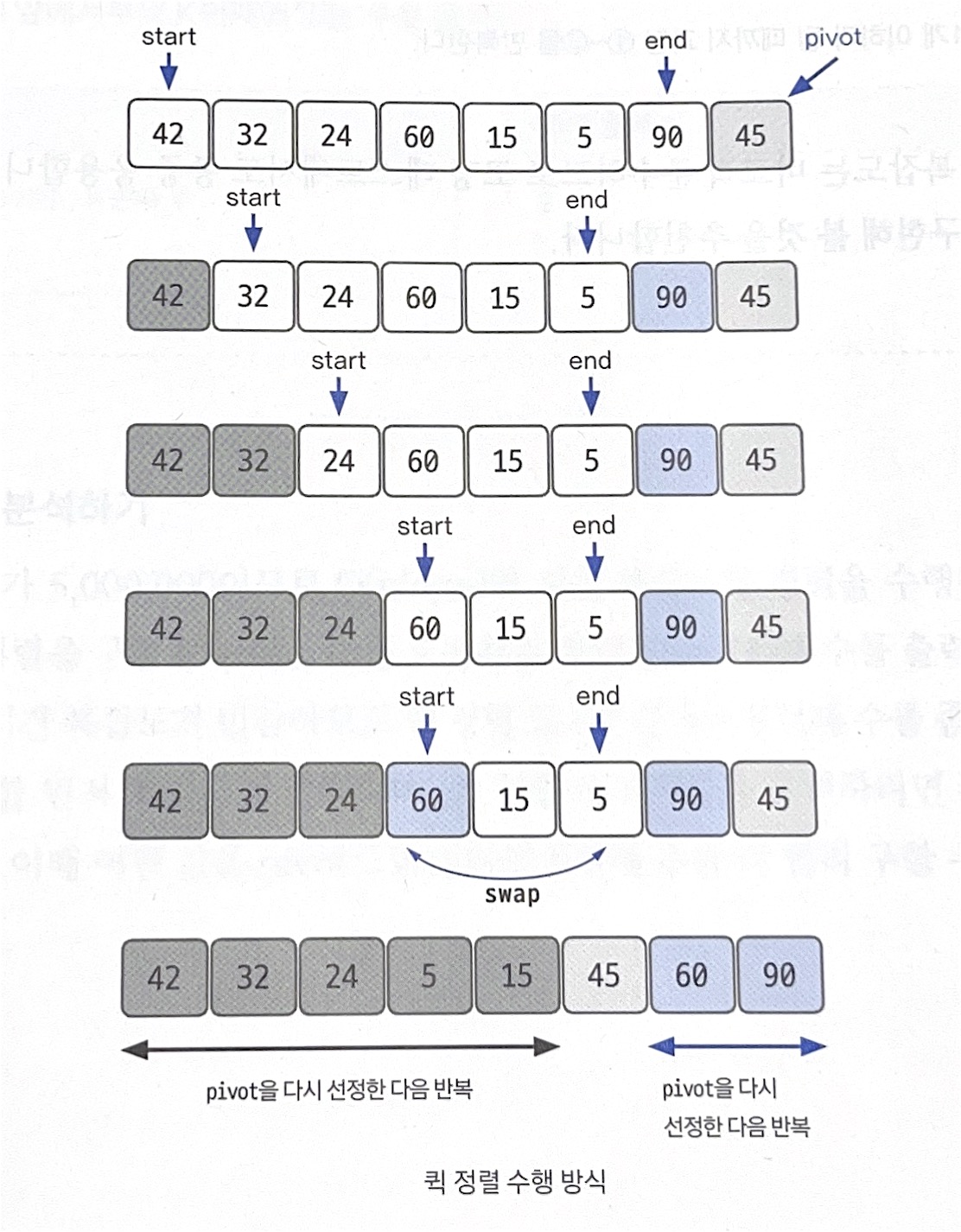
📌 퀵 정렬 장점
- 속도가 빠르다
- 시간 복잡도가 O(nlogn)으로 이전에 살펴본 버블 정렬, 삽입 정렬, 선택 정렬에 비해 빠른 편이다
- 리스트를 재귀적으로 나누고 각 부분 리스트를 효율적으로 정렬하기 때문이다
- 추가 메모리 공간을 필요로 하지 않는다
- 제자리 정렬(in-place sorting) 알고리즘으로, 데이터를 정렬하는 동안 추가적인 배열이나 리스트를 생성하지 않습니다.
단, 재귀 호출에 따라 함수 호출 스택에 메모리를 사용하므로, 최악의 경우 스택 깊이가 깊어질 수 있습니다. - 일반적으로 추가 공간 복잡도는 O(logn)
- 제자리 정렬(in-place sorting) 알고리즘으로, 데이터를 정렬하는 동안 추가적인 배열이나 리스트를 생성하지 않습니다.
📌 퀵 정렬 단점
- 정렬된 리스트에 대해서 수행시간이 많이 걸린다
- 방지하기 위해 pivot을 중간 값으로 선택하는 등 균등하게 분할할 수 있는 데이터를 선택하자
✅ 다음 게시글에서 예제 문제로 더 자세히 이해해보도록 하겠습니다!
[JAVA][Baekjoon] 11004번 K번째 수 🌟🌟🌟
https://www.acmicpc.net/problem/11004 📌 접근 방식N의 최대값이 5백만이기 때문에 단순히 Arrays.sort() 같은 걸로 풀면 시간 초과가 날 확률이 높아요. 그래서 퀵 정렬을 사용해 풀어보았습니다. [알고리
nyeroni.tistory.com

728x90
반응형
'CS > 알고리즘' 카테고리의 다른 글
| [알고리즘] 기수 정렬(Radix Sort)이란? (0) | 2025.01.03 |
|---|---|
| [알고리즘] 병합 정렬(Merge Sort)이란? (0) | 2025.01.03 |
| [알고리즘] 삽입 정렬(Insertion Sort)이란? (0) | 2025.01.02 |
| [알고리즘] 선택 정렬(Selectio Sort)이란? (2) | 2025.01.02 |
| [알고리즘] 버블 정렬(Bubble Sort)이란? (1) | 2024.05.12 |